


Understand Hidden Emotions Better: The Power of Sentiment Analysis Models
From Traditional Machine Learning to AI with LLM.


Did you ever wonder how public opinion shapes elections or how indices like the Bitcoin Fear and Greed Index are calculated?
At the core of these questions is a fascinating tool: sentiment analysis.
Sentiment analysis helps us interpret emotions in language, uncovering public opinion, trends, and even predicting behaviors. It’s where computers meet human emotions — a mix of art and science.
I’ve always been curious at how sentiment analysis works and its real-world applications. In this article, I’ll take you through my step-by-step exploration of its models, tools, and uses.
What is Sentiment Analysis?
Sentiment analysis is the process of determining the emotional tone behind words. It helps categorize text as positive, negative, or neutral, making it a powerful tool for understanding customer feedback, social media opinions, and emotional trends over time.
The basic flow of sentiment analysis includes:
Text Preprocessing: Cleaning and preparing the data.
Feature Extraction: Tokenizing text and converting it into a format understandable by models.
Classification: Using machine learning or lexicon-based methods to predict sentiment.
Models of Sentiment Analysis
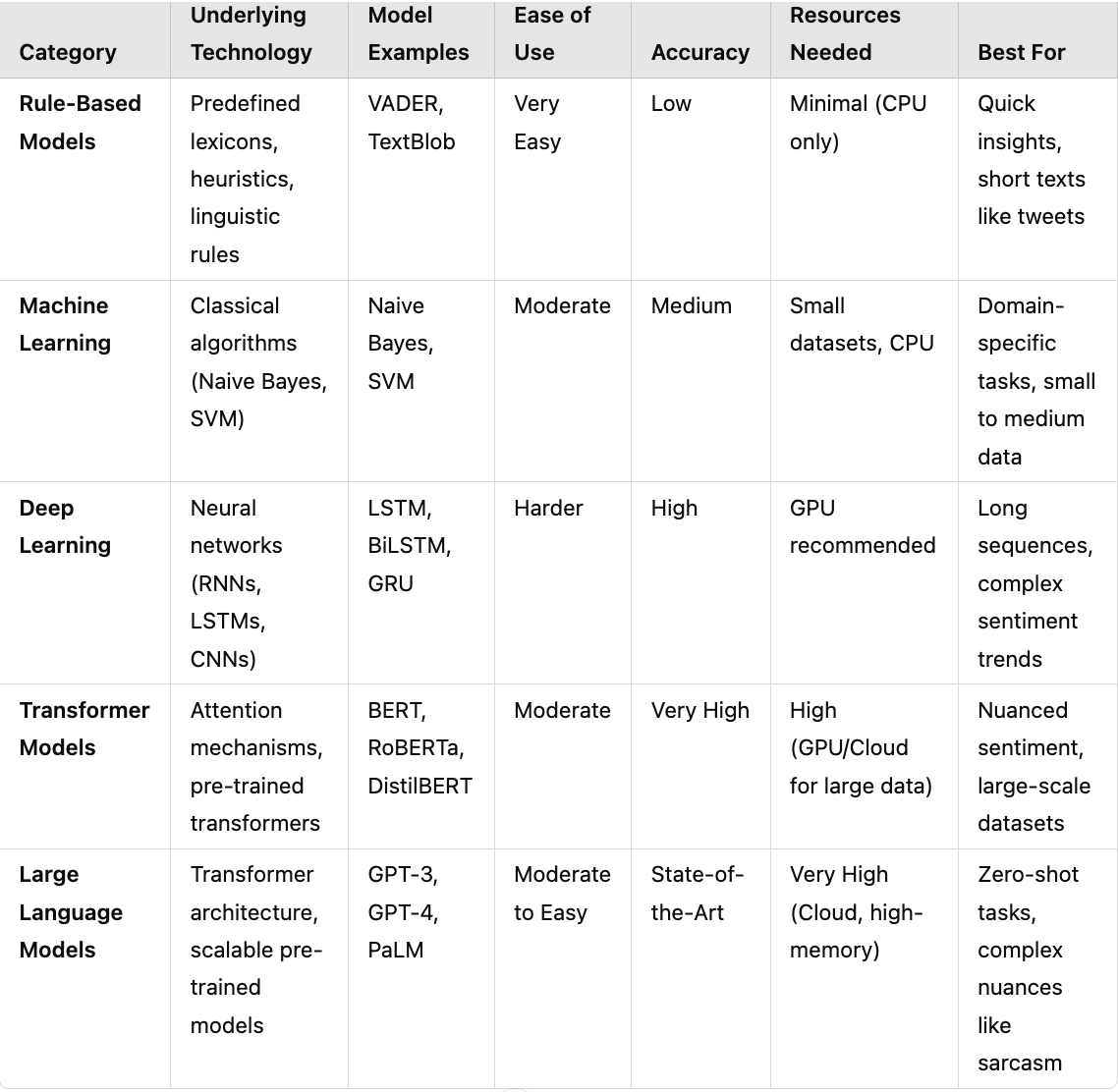
Sentiment analysis models can be grouped into traditional methods and large language models (LLMs).
1. Rule-Based Models
What they do: Use predefined dictionaries of words (lexicons) with assigned sentiment scores.
How they work: Words like “good” are positive, “bad” are negative, and simple rules (e.g., “not good” = negative) are applied to calculate overall sentiment.
Underlying Technology:
Linguistic rules.
Hand-crafted dictionaries of sentiment scores.
Examples:
VADER: Optimized for short texts like tweets, handling emojis and negations.
TextBlob: Assigns polarity and subjectivity scores to words.
💡 Best for: Quick, lightweight tasks like determining if a tweet is positive, negative, or neutral. However, they struggle with sarcasm or nuanced language.
2. Machine Learning Models
What they do: Train on labeled datasets to classify sentiment.
How they work: Features like term frequency (TF-IDF) or word counts are extracted, and algorithms like Naive Bayes or Support Vector Machines (SVM) classify text.
Underlying Technology:
Feature extraction methods: TF-IDF, n-grams, bag-of-words.
Classical machine learning algorithms (e.g., Naive Bayes, SVM).
💡 Best for: Projects with sufficient labeled data and structured inputs. While effective, these models lack generalization and require specific training.
3. Transformer Models
What they do: Capture local and global relationships in text using attention mechanisms.
How they work: Pre-trained on massive datasets, transformers like BERT and GPT can be fine-tuned for sentiment tasks or used out-of-the-box for zero-shot analysis.
Underlying Technology:
Transformer-based architecture.
Massive pre-training on diverse datasets.
Examples:
BERT: Understands word context from both directions.
RoBERTa: An optimized version of BERT for nuanced tasks.
💡 Best for: Complex language tasks and domain-specific analysis.
4. Large Language Models (LLMs)
What they do: Use massive pre-trained datasets to predict sentiment without additional training (zero-shot learning).
How they work: Models like GPT-4 understand context, even in sarcastic or ambiguous sentences.
Underlying Technology:
Transformer architecture with self-attention.
Transfer learning via fine-tuning on task-specific datasets.
Tokenization strategies like WordPiece or Byte-Pair Encoding (BPE).
💡 Best for: Situations where minimal setup is needed or nuanced, multilingual analysis is required.
Ease of Use
Traditional Models: Perfect for Simple Projects
Lexicon-based tools like TextBlob are easy to set up and provide quick results. For example:
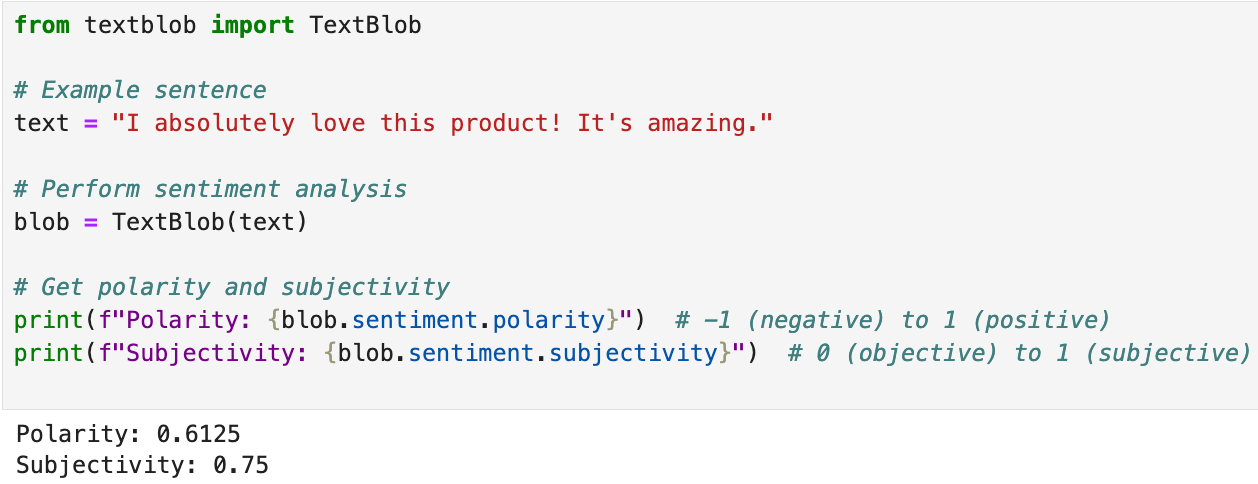
Polarity:
0.6125indicates positive sentiment.Subjectivity:
0.75suggests the text is mostly opinion-based.
Transformer Models: Powerful Yet Resource-Intensive
Pre-trained models like DistilBERT are easy to use with Hugging Face’s pipeline API:
from transformers import pipeline
sentiment_analyzer = pipeline("sentiment-analysis")
text = "I absolutely love this product! It's amazing."
result = sentiment_analyzer(text)
print(result)
# Output: [{'label': 'POSITIVE', 'score': 0.8198}]💡 While transformers are highly accurate, they require more computational resources. Running large models like GPT-4 on local machines may cause memory issues. For advanced tasks, use cloud GPUs or optimized environments.
In fact, I was never able to finish one analysis within my personal Jupyter Notebook.
Applications of Sentiment Analysis
Returning to the presidential election example mentioned earlier, sentiment analysis plays a crucial role in politics by helping politicians and analysts to:
Gauge Public Sentiment: Monitor how voters feel about policies or candidates during campaigns.
Refine Campaign Strategies: Adjust messaging and outreach efforts based on voter sentiment.
A notable example is the 2016 US Presidential Election, where campaigns leveraged sentiment analysis of social media posts to craft targeted ad placements and messaging strategies. [source]
Sentiment analysis is transforming industries far beyond politics. Here’s how it’s being used:
1. Politics
Example: During elections, campaigns analyze voter sentiment on social media to refine messaging strategies.
2. Finance
Example: Predicting stock trends based on public sentiment in financial news and tweets.
3. Healthcare
Example: Analyzing patient feedback to improve care and identify emerging health concerns.
4. Brand Management
Example: Monitoring how customers feel about products and services in real time.
Challenges of Sentiment Analysis
While sentiment analysis is a powerful tool, it’s not without its challenges. Here are some of the most common limitations that can impact its effectiveness:
Sarcasm: Models struggle with irony, e.g., “Oh, great, another Monday!”
Ambiguity: Words like “fine” can have multiple interpretations depending on context.
Domain-Specificity: Terms like “critical” in healthcare or finance require specialized training for accuracy.
Multilingual Data: Sentiments across languages can be misclassified without cultural or linguistic context.
Mixed Sentiments: Sentences like “Great camera, awful battery life” challenge binary classifications.
Understanding these challenges helps in interpreting results and tailoring models for better accuracy.
Wrapping Up
Sentiment analysis is more than just a buzzword — it’s a powerful tool for understanding emotions in text.
Whether you’re using quick tools like VADER and TextBlob, or exploring advanced transformers like BERT and GPT-4, there’s a solution for every project.
Takeaways:
Use traditional models for lightweight, quick tasks.
Try transformers for nuanced, high-accuracy sentiment analysis.
Explore LLMs for zero-shot or few-shot applications without training.
Now it’s your turn to experiment. Analyze text, discover trends, and uncover the hidden emotions in your data. What will you find? Let me know — I’d love to hear about your projects!